AI 아키텍쳐의 발전 과정
1. 규칙 기반 AI (1950~1980) : 지능 자체를 규칙을 만들어서 개발하려고 함
- 한계 : 세상에 어느 누가 지식을 규칙으로 전부 정의할 수 있겠음?
- 규칙 수가 개 많아져서 Combinatorial Explosion (조합 폭발) 현상이 나타남
2. 퍼셉트론 (1957년, Frank Rosenblatt) : 생물의 “뉴런”을 수학 모델로 만듬
입력 x
↓
가중치(weight)
↓
합산
↓
활성화 함수
↓
출력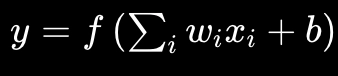
- 한계 : 선형 분리 불가능 문제
- 선형 분리 : 퍼셉트론은 기본적으로 선 하나를 그어서 그걸 기준으로 데이터를 분류함.
- 분리가 되는 예시 :
- 빨간 선 위에 있으면 적군, 아래에 있으면 아군
- 분리가 되는 예시 :
- 선형 분리 : 퍼셉트론은 기본적으로 선 하나를 그어서 그걸 기준으로 데이터를 분류함.
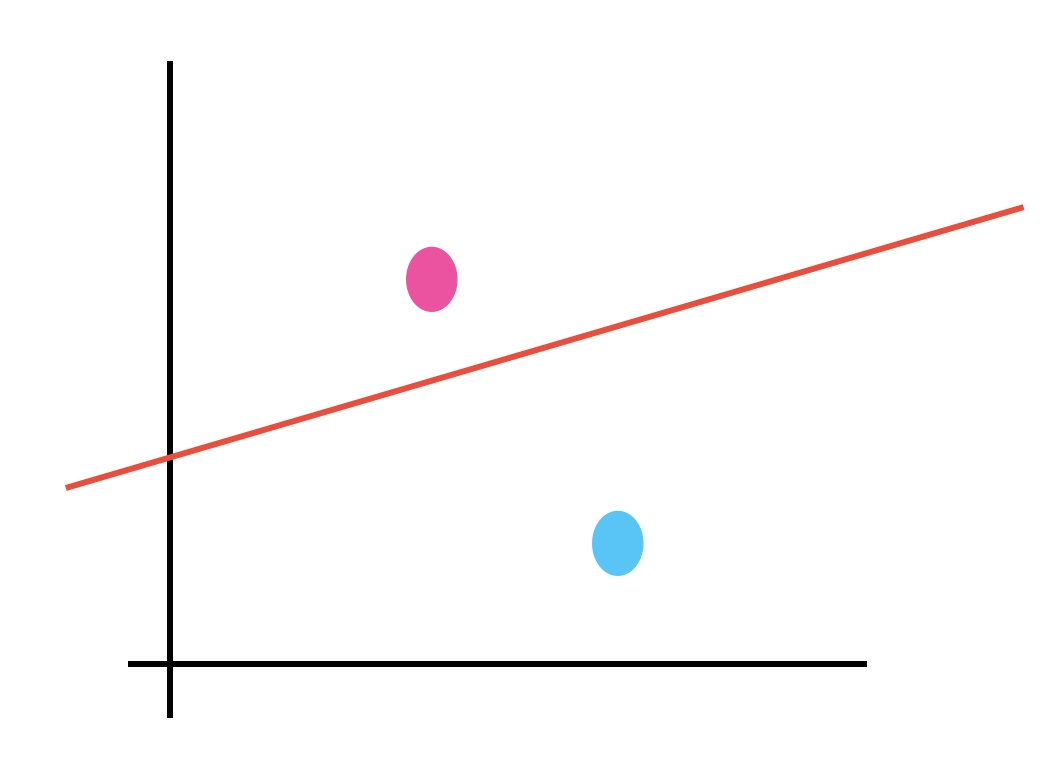
-
분리 안되는 예시 : XOR
- XOR 진리표 : 두 값이 달라야 1임
| a | b | xor 결과 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
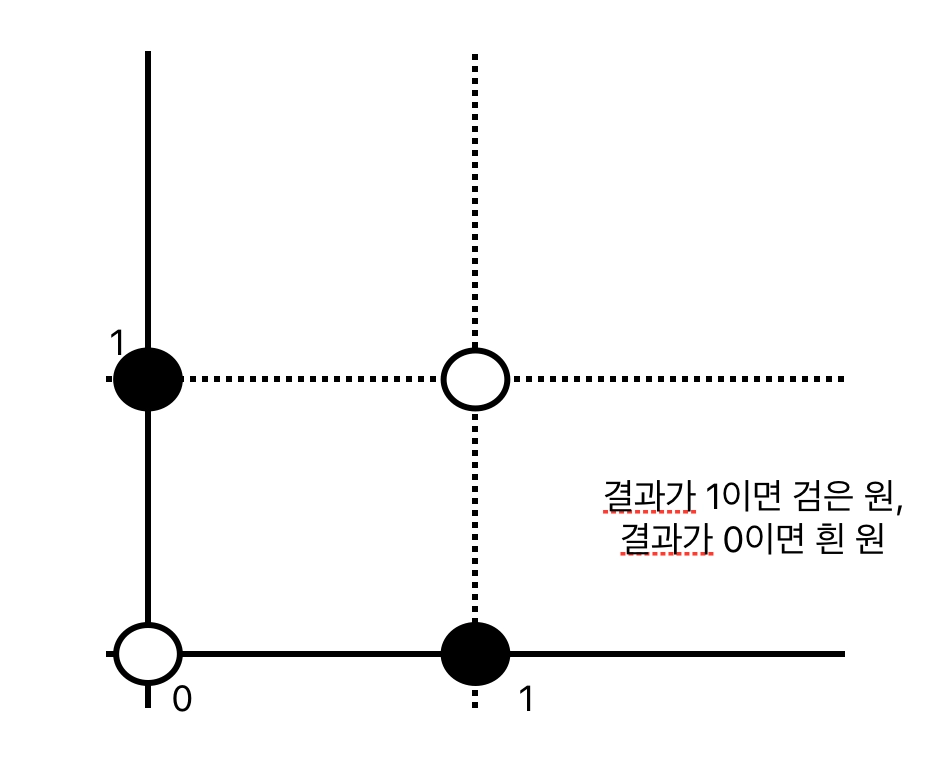 |
- 이거는 선 하나를 그어서 나눌 수가 없음 ⇒ 선형 분리 불가능 문제
3. 다층 신경망 (1980 ~ 1990) : 퍼셉트론을 여러개 씀
입력층
↓
은닉층
↓
출력층- 이 때 비선형 문제도 해결이 됐음.
- 이때 등장한 기술이 Backpropagation, 역전파 알고리즘임
- 출력층의 결과에서 발견된 오차를 앞단에 있는 은닉층, 입력층 순서로 “입력과 역순으로” 가중치를 전달한다고 해서 역전파라는 이름이 붙음.
- 한계 : Gradient Vanishing 문제
- 기본적으로 알아야되는게 역전파는 앞단 레이어로 갈 수록 미분값을 곱함
- 미분값을 곱할수록 값이 작아짐
- 그러면 가운데에 은닉층이 많아지고 신경망이 커지면 초기층에 전달되는 Gradient(기울기) 자체가 거의 없어짐 ⇒ Gradient Vanishing (기울기 소실)
- 그 얘기는 초기층이 조정되고 업데이트 되는 정도가 매우 작거나 사실상 없어짐
- ⇒ 신경망이 깊어질수록 역으로 성능이 떨어지는 문제 발생
4. CNN (1990 ~ 2010) : Convolutional Neural Network, 합성곱 신경망. 이미지 처리 분야 시작
- 위에 MLP 까지는 공간 정보를 잘 활용하지 못했음.
- 이 시기에 등장한 기술이 합성곱 (Convolution).
- 이미지를 “커널” (필터)을 걸쳐 연산하는 작업임
5. RNN : Recurrent Neural Network, 순환 신경망
- 순서가 중요한 시계열, 시퀀스 데이터 등을 처리하기 위해 등장함.
- 이전 상태를 다음 데이터 처리에 활용함
x1 → h1 (hidden state 1)
↓
x2 → h2
↓
x3 → h3- 한계 : 긴 문장은 잘 처리하지 못했음
6. LSTM/GRU (1997~) : RNN의 한계 개선 시도
- LSTM : Long Short-Term Memory
- GRU : Gated Recurrent Unit
- 이전의 “모든 상태”를 기억하는게 아니고, 일부만 선택해서 기억하는데 그걸 “게이트”를 사용해서 함
- Forget Gate
- Input Gate
- Output Gate
- 한계 : 여전히 느렸음
7. Attention 메커니즘 (2014 ~ ) : 기억을 특정 부분을 “집중해서” 하자
- 기존 RNN 기반 데이터 생성은 아래의 규칙을 따랐음
- 입력 문장 전체를 “하나의 고정 크기 벡터”로 만들어서 그걸 출력
- 근데 이러다보니 문장이 길어질수록 애가 제대로 처리를 못함
- Attention 메커니즘에서는 집중할 데이터에 대한 연산이 들어가고, “입력 문장 전체를 다시 참조”할 수 있게 함
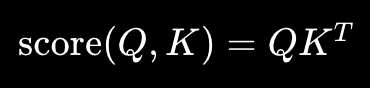
- 이 Attention 메커니즘은 굉장히 많이 확장됨
- Self-Attention : 입력 문장 내에서의 문맥을 찾음. 각 단어가 다른 단어를 얼마나 참고할지를 계산함
- Cross-Attention : 번역 중 원문 다시 보기를 함. 출력하는 동안에도 입력 문장을 참고함
- Multi-Head-Attention : 여러 관점에서 어텐션 메커니즘을 돌림.
8. Transformer (2017) : RNN을 없애버려
- 제목 그대로 RNN, 순환 신경망 자체를 아예 빼버림
- 구조 : 입력 → 인코더 → 문맥 표현 → 디코더 → 출력
입력 문장
↓
Encoder
↓
문맥 표현(Context Representation)
↓
Decoder
↓
출력 문장 생성- 주요 기술 : Multi-Head Attention, Positional Encoding, FFN (Feed Forward Network)
- RNN 대신에 Multi-Head Attention을 사용함
| Head | 역할 예시 |
|---|---|
| 1 | 문법 |
| 2 | 의미 |
| 3 | 장거리 관계 |
- Positional Encoding
- RNN을 뺀 순간 얘네는 입력된 데이터의 “순서를 고려하지 않고” 동시에 받아들이기 때문에, 문장에서 단어의 순서를 몰랐음.
- 애초에 어텐션 메커니즘은 사실상 집합 연산에 가까움
- 그래서 그 순서를 지키도록 하기 위해 Positional Encoding, 즉 위치 정보를 추가하는 작업을 진행함.
- 최초의 트랜스포머 모델에는 포지셔널 인코딩에 sin, cos 연산이 들어갔음
- 최근의 모델에는 sin, cos 대신에 RoPE, ALiBi 등을 쓴다고 함
- RoPE : 위치 정보를 “벡터의 회전”으로 표현함. 장거리 문맥 처리에 강함.
- FFN (Feed Forward Network)
- 어텐션 지나오고 FFN(비선형) 거침
- 각 토큰 별로 작은 MLP를 수행함
- 어텐션만 하면 사실 단어가 어떤 다른 단어랑 관계있는지 계산만 하는거고, 원하는 출력결과를 뽑아내는건 FFN에서 함
- (GPT 피셜) : 어텐션은 “어떤 단어를 참고해야하지?” 고, FFN은 “이 문맥을 어떻게 해석하지?” 에 가까움
참고 : 인코더와 디코더
-
인코더 : 의미 이해
-
디코더 : 문장 생성
-
학습 방법
- 인코더 :
- Self Attention으로 자기 문장 내부의 단어끼리 연관도 계산
- MLM (밑에 BERT 계열에서 설명) 사용해서 추론 학습
- FFN으로 토큰 별 MLP 수행해서 문맥 해석
- 디코더 :
- Cross Attention으로 현재 생성 상태와 인코더의 출력 간 연관도 계산해서 출력
- 인코더 :
9. BERT 계열 (2018) : 이해를 잘 하자
- BERT : Bidirectional Encoder Representations from Transformers
- 문맥을 왼쪽→오른쪽으로만 파악하는게 아니고 양방향(Bidirectional)으로 이해함
- BERT는 두 가지 방법으로 사전 훈련을 진행함
- MLM : Masked Language Model
- 입력 텍스트의 15%를 마스킹해서 안보이게 하고 추론하도록 함
- NSP : Next Sentence Prediction
- 두 문장을 주고, 그 두 문장이 이어지는 문장인지 맞추는 방식으로 작업함.
- MLM : Masked Language Model
- 다만 생성 능력 자체는 약했음. 왜냐면 인코더로만 만들어진 모델이었기 때문.
10. GPT 계열 : 생성을 잘 하자
- GPT : Generative Pre-trained Transformer
- 이름 보면 알겠지만 “생성형” 임. 디코더만으로 이루어진 모델임.
- 그리고 Pre-trained은 대규모 텍스트를 사용해 이미 학습된 모델이라는 뜻
- Autoregressive Generation (자기회귀 생성) 방식 사용
- 이전 토큰 내용 기반으로 다음 토큰 내용을 추론함
- 미래의 토큰을 못보게 마스크 처리한 Masked Self-Attention 사용
- 아래는 GPT 버전별 변천사 (ChatGPT 피셜)
| 요소 | GPT | GPT-2 | GPT-3 |
|---|---|---|---|
| 모델 크기 | 작음 | 중간 | 매우 큼 |
| 데이터셋 | 제한적 | 대규모 웹 | 인터넷급 |
| 생성 능력 | 실험적 | 자연스러움 급상승 | 범용성 폭발 |
| Emergent Ability | 거의 없음 | 일부 등장 | 본격 등장 |
- 여기서 Emergent Ability 라는 용어가 나옴.
- Emergent Ability : LLM이 파라미터 수, 데이터량, 컴퓨팅 파워가 일정 규모를 넘었을 때, 작은 모델에서는 없던 새로운 능력이나 패턴을 갑작스럽게 스스로 획득하는 현상
- 특히 GPT 버전 업에서는 아래와 같은 현상이 나타났음
- zero-shot capability : 한 번도 안해본 작업을 시키면 나름 함
- few-shot learning : 예시 몇 개 보여주면 그대로 따라할 수 있게됨
- 특히 GPT 버전 업에서는 아래와 같은 현상이 나타났음
11. RLHF (2022~) : 사람의 피드백을 들어보자
- GPT에서 일단 “데이터를 죄다 때려넣으면 애가 똑똑해짐” 을 확인했음
- 문제가 있다면 데이터에 따라서 공격적이거나 혐오표현을 배울 수도 있다는 것.
- 그래서 사람의 피드백을 수용하도록 변경됨
- RLHF : Reinforcement Learning from Human Feedback
- 실제 사람 반응을 보고 강화학습하는 것
- 또한 PPO(Proximal Policy Optimization)을 활용하기도 함
- 기존 정책 대비 새 정책 수용의 확률비를 지정해서, 한번에 확 바뀌지 않도록 정해둠
- 여러 미니배치에 대해서 기울기 조정을 진행함
12. Instruction Tuning : 사람이 시키는걸 잘 듣자
- 사람의 입력과 그에 대한 출력을 기반으로 학습
- Supervised fine-tuning 형태
13. RAG : LLM 안에 데이터로 없으면 검색을 해
- RAG : Retrieval-Augmented Generation (검색 증강 생성)
- 문서를 벡터화 한 다음에 외부 검색 시스템에 연결해서 그에 맞는 데이터를 검색함
- 참고로 유사도는 cos 유사도를 사용함